
空洞卷积(dilated convolution)
发布时间:2020-11-23 栏目:人工智能, 图像处理, 深度学习 评论:0 Comments
论文:Multi-scale context aggregation with dilated convolutions
dilated conv,中文可以叫做空洞卷积或者扩张卷积。
首先是诞生背景,在图像分割领域,图像输入到CNN(典型的网络比如FCN[3])中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预测是pixel-wise的输出,所以要将pooling后较小的图像尺寸upsampling到原始的图像尺寸进行预测(upsampling一般采用deconv反卷积操作),之前的pooling操作使得每个pixel预测都能看到较大感受野信息。因此图像分割FCN中有两个关键,一个是pooling减小图像尺寸增大感受野,另一个是upsampling扩大图像尺寸。在先减小再增大尺寸的过程中,肯定有一些信息损失掉了,那么能不能设计一种新的操作,不通过pooling也能有较大的感受野看到更多的信息呢?答案就是dilated conv。
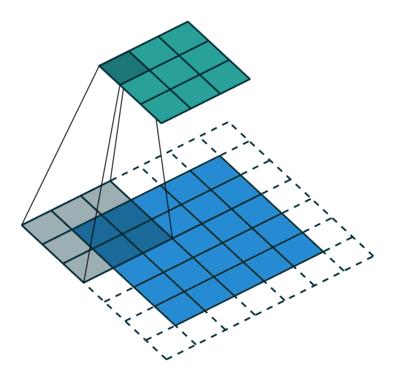
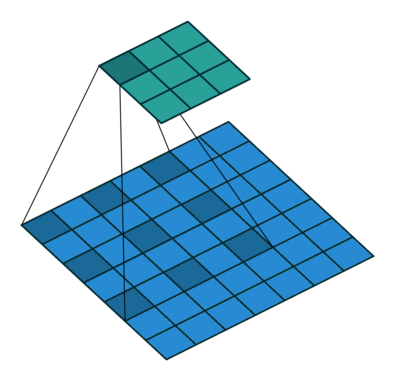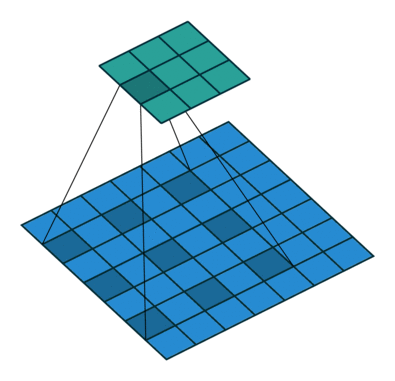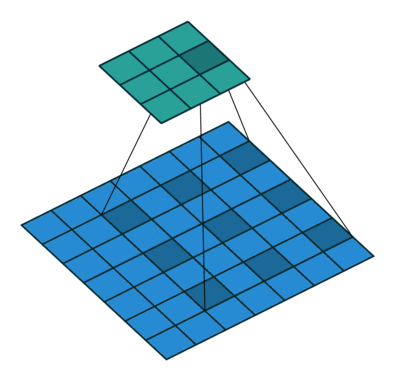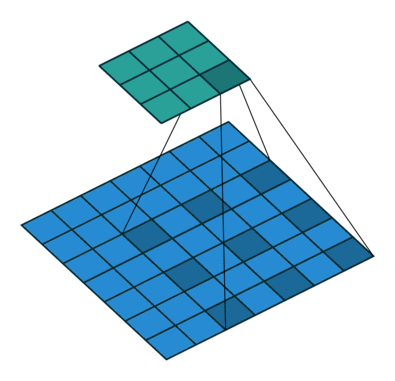
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv,比如图像分割[3]、语音合成WaveNet[2]、机器翻译ByteNet[1]中。简单贴下ByteNet和WaveNet用到的dilated conv结构,可以更形象的了解dilated conv本身。
而dilated conv不是在像素之间padding空白的像素,而是在已有的像素上,skip掉一些像素,或者输入不变,对conv的kernel参数中插一些0的weight,达到一次卷积看到的空间范围变大的目的。
当然将普通的卷积stride步长设为大于1,也会达到增加感受野的效果,但是stride大于1就会导致downsampling,图像尺寸变小。
参考:
https://blog.csdn.net/suixinsuiyuan33/article/details/79451069





